![[程序员的自我修养] 理解编译到链接的过程](https://dxyt-july-image.oss-cn-beijing.aliyuncs.com/image-20230414151451674.webp)
Table of Contents
程序的编译及链接 Link to 程序的编译及链接
在学习C语言的过程中, 每一个 .c 文件都会经过编译链接等 预处理 操作才能成为一个 .exe 的可执行文件的
这些 预处理 过程到底是如何进行的, 就是本篇文章的内容
一、程序的翻译环境和执行环境 Link to 一、程序的翻译环境和执行环境
一般写出的 .c 后缀的 源代码文件, 是不能直接执行的。 类似 .c 的源代码文件要变成 类似 .exe 后缀的 可执行文件, 再到可执行 程序的运行 实现 是要经过两个环境的: 翻译环境 执行环境
大致的过程是:
- 一个源代码文件, 由翻译环境翻译为 计算机能够直接看懂的 二进制指令(机器指令), 即生成可执行程序: 类似
.exe后缀的文件(不同系统环境下的可执行程序的后缀是不同的) - 可执行 程序的运行 实现, 就需要 通过运行环境 来实现
即:
在ANSI C的任何一种实现中, 存在两个不同的环境。
第1种是翻译环境, 在这个环境中源代码被转换为可执行的机器指令。
第2种是执行环境, 它用于实际执行代码
1. 1 翻译环境 Link to 1. 1 翻译环境
翻译环境可以简单的分为两个过程: 编译 和 链接 编译的作用是, 将一个项目中的每一个源代码文件(.c 后缀等), 都单独处理为 对应的目标文件(VS编译器 环境下.obj 后缀, GCC编译器 环境下 .o后缀)
而链接, 则是将编译生成的 .obj 目标文件与所其涉及到的静态库, 一起进行链接, 最终生成 .exe 后缀的可执行文件
📌
在这一整个过程中,
编译器来完成编译操作,链接器来完成链接操作
在编译链接的过程中, 除了源文件(.c后缀)和目标文件(.obj或o后缀), 还提到了一个名词: 静态库 也可以被称作 静态链接库。
📌
静态库链接库是什么?编写C语言代码使用的一些函数, 例如:
printfscanf等等, 这些函数, 并不属于编写者所自定义的函数。这些函数是由 C 语言默认提供的。这些由 C 语言默认提供的函数, 一般都存放在各自的库中:
像以上
LIBC.LIB、LIBCMT.LIB、MSVCRT.LIB都属于静态库,printf函数就存在于这三个静态链接库中

如果在编写的 源代码文件 中, 使用到了存在于某些 静态链接库里的库函数 那么在链接的时候, 就会将 所使用函数的静态库 与 编译生成的目标文件 一起链接起来, 以致于可执行程序可以正常执行。
以上的编译过程可以细分为三个过程: 预编译、编译、汇编
1.2 翻译详解 Link to 1.2 翻译详解
上面了解到, 由源代码到可执行程序的过程是要经过 翻译环境 的一系列操作的, 翻译环境大方面分为 编译 链接 两个大过程, 而编译又可以细分为: 预编译( 预处理 )、编译、汇编 三个详细过程。 下面是编译的三个详细过程的详解:
以下 均为 Linux平台-GCC编译环境下 的演示效果
1.2.1 预编译 Link to 1.2.1 预编译
预编译是干什么的? 预编译, 一般进行三项操作:
- 对 头文件的包含、展开
- 对 注释的删除
- 对
#define所宏定义符号的转换
干巴巴的只用文字表述, 其实没有办法简单直观的理解这三项操作, 所以用图片来演示:
对三项操作一 一进行展示:
📌
对头文件的包含、展开
Linux 环境下编写简单的一段代码:
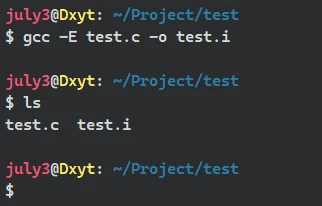
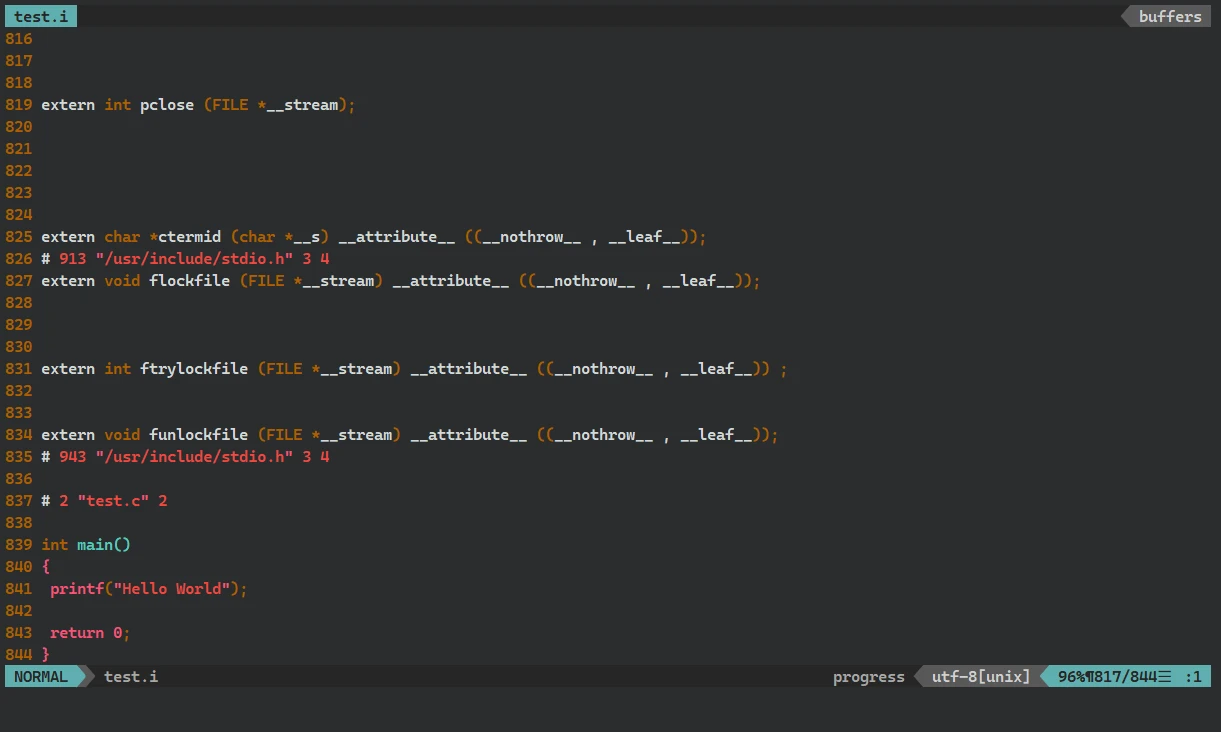
#include <stdio.h> //头文件 int main() { printf("Hello World"); return 0; }然后用 GCC 编译器对 test.c 文件进行 预处理, 并将 预处理 后的文件信息输出至 test.i 文件中:
✔️小知识:
gcc -E (源代码文件) 或 gcc (源代码文件) -E对源代码进行预编译
gcc -E (源代码文件) -o (指定预处理文件)或 gcc (源代码文件) -E -o (指定预处理文件)对源代码进行 预处理 并输出至指定文件内可以看到 路径下生成 test.i 文件, 最后一部分内容为:
除了最后的几行代码, 以上并不是原文件中的代码, 并且 原代码文件中
#include <stdio.h>对头文件的包含消失不见以上的内容与 stdio.h 部分内容做对比:
stdio.h部分内容:
很容易发现, 两文件中关键代码是相同的
所以可以肯定,
预编译过程中, 编译器对源代码进行了 头文件的包含、展开的操作
📌
对注释的删除
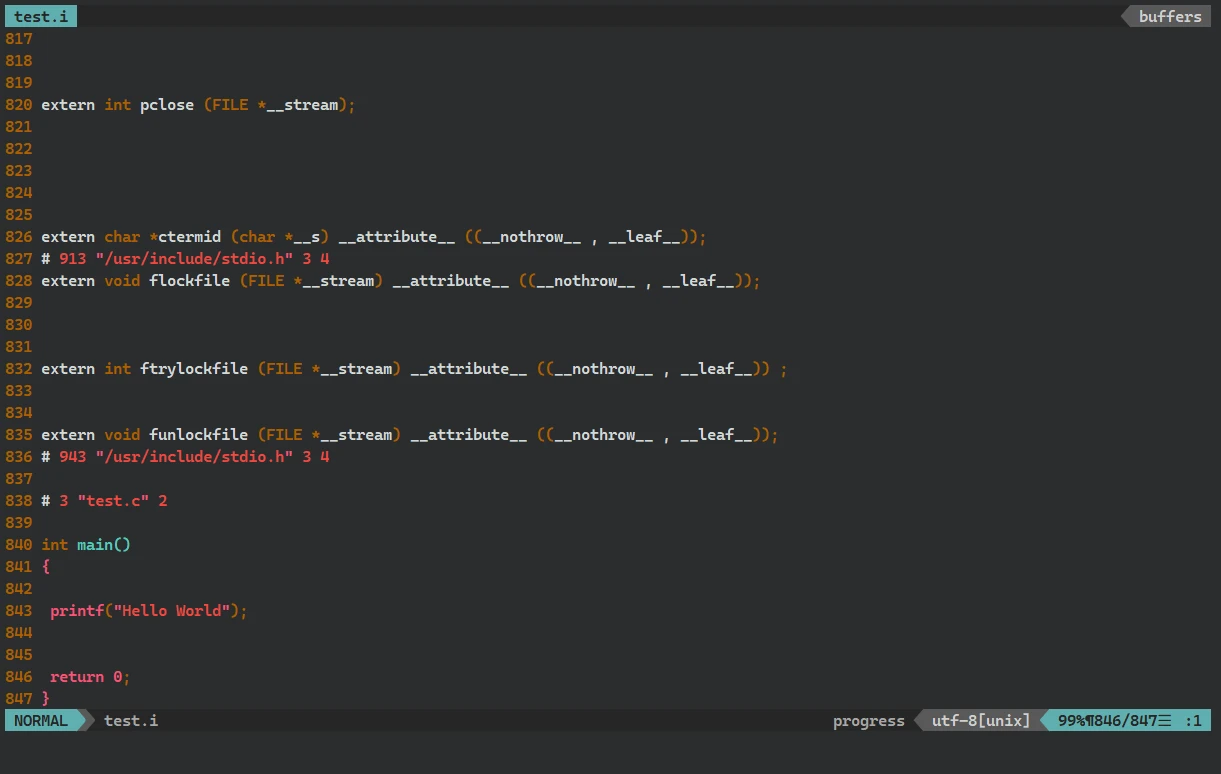
在上面两个文件做对比的时候, 细心观察可以发现, 两个文件所包含的相同的头文件的代码行数是不相同的
再一对比, 可以看出
test.i文件中并没有蓝色的注释部分说明预编译, 对源代码也进行了 删除注释 的操作
还有一个更直观的 展示方法(使用以下代码进行预编译操作)(可以直接再
test.c文件中添加):// 这是头文件的包含 #include <stido.h> // 这是程序主函数 int main() { // 这是一个 printf 函数 printf("Hello World") // 这是主函数的返回操作 return 0; }对以上代码进行预编译操作, 并查看预编译后的文件内容:
同样可以看出, 预编译后的代码中, 注释内容被删除了, 也可以说是被空格替换掉了 所以,
预编译过程中, 编译器源代码进行了 删除注释 的操作
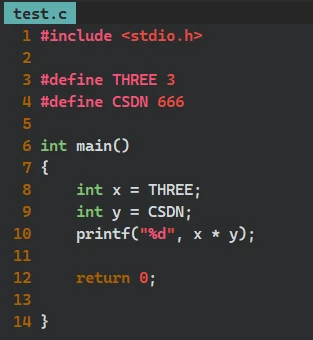
📌 对 #define 宏定义符号的替换 还是不同的代码, 同样的操作 使用以下代码:
#include <stdio.h> #define 3 THREE #define 666 CSDN int main() { int x = THREE; int y = CSDN; printf("%d", x * y); return 0; }
预编译处理:
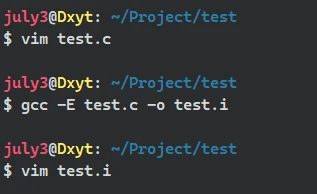
test.i部分内容:
源代码中的 两句宏定义 语句被删除, 函数中使用的宏定义符号 被替换为 原本的数值
可以说明,
预编译过程中, 编译器对源代码进行了 替换宏定义符号 的操作
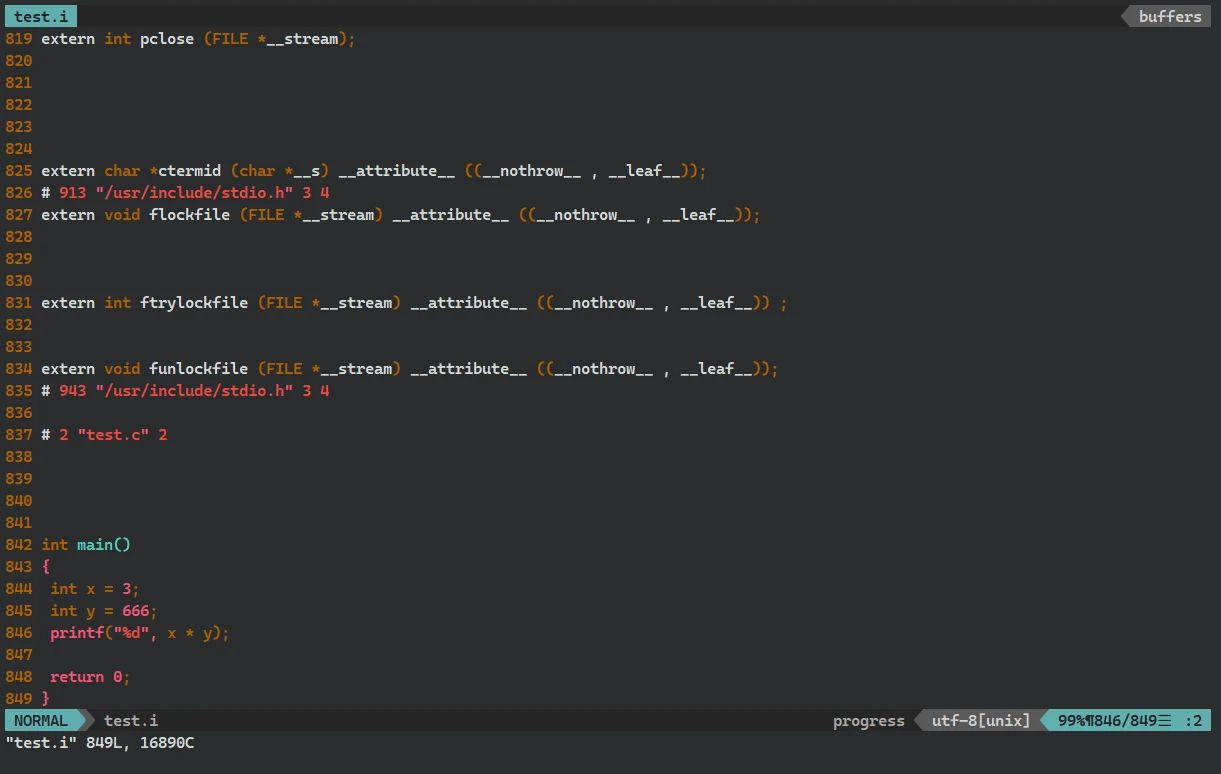
以上的三种示例, 可以说明预编译过程 一般是对源代码进行的一些 文本的删除、替换、文件文本的包含、展开等。 所以可以说, 预编译 一般是对源代码 进行一系列的文本操作
1.2.2 编译 Link to 1.2.2 编译
经过预编译后的源代码文件, 已经除去了许多对计算机来说没有用的信息(比如 注释, 注释一般是写给操作者看的, 计算机不需要注释)
预编译 的作用一般是对源代码进行 文本操作 , 那么 编译 的具体作用是什么呢?
我们通过对上面某个已经 经过预编译的文件 进行编译:
📌
✔️小知识:
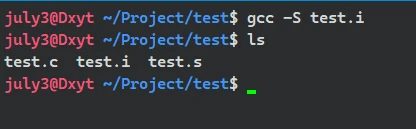
gcc -S (经过预编译的文件) 或 gcc (经过预编译的文件) -S
可以对已经经过预编译的文件进行编译, 自动输出到 文件对应的以.s为后缀的文件查看
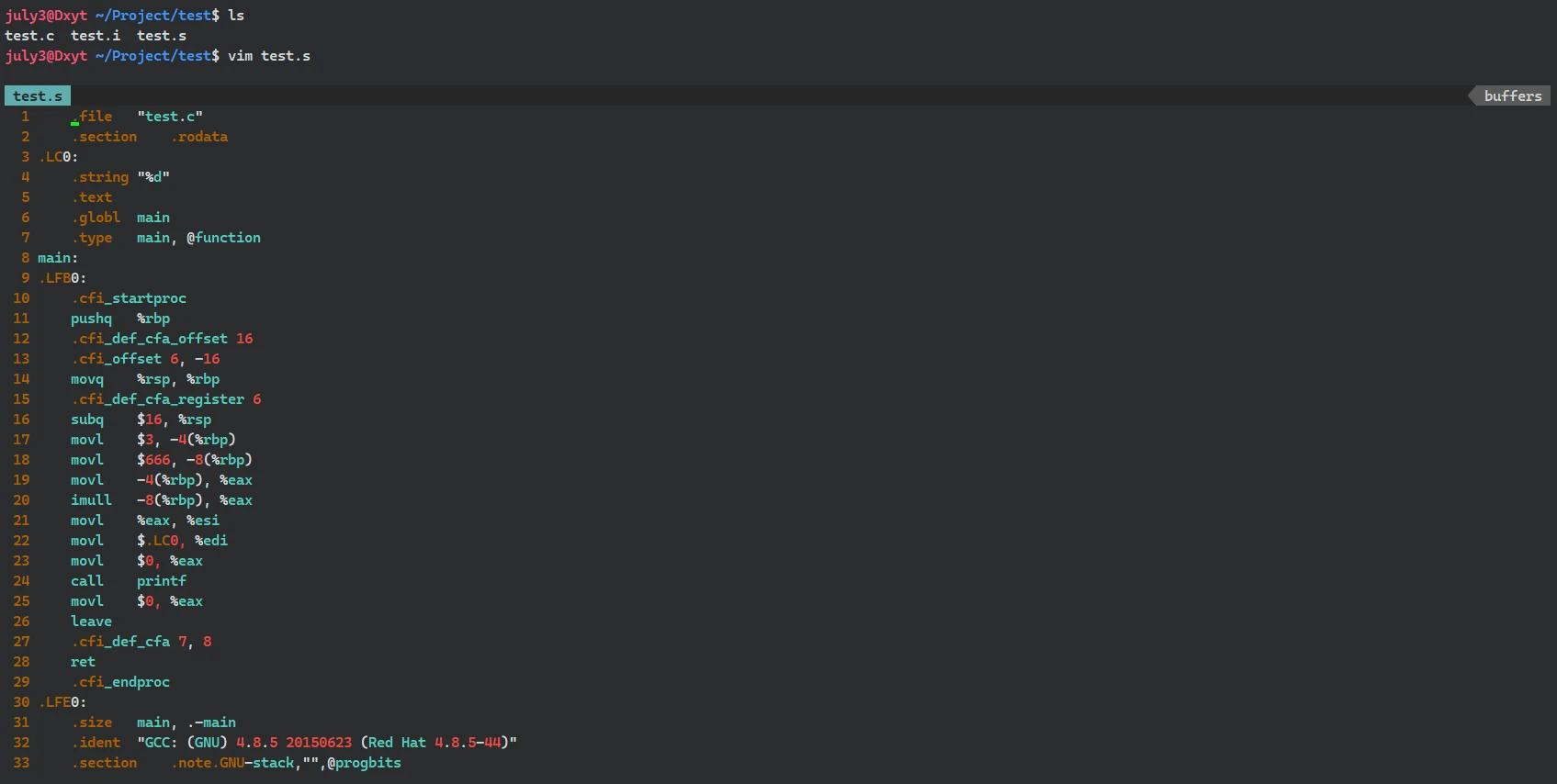
test.s的具体内容:
查看
test.s的内容不难发现, 它的内容都是汇编代码所以, 预编译之后的编译操作, 其实是将
经过预编译的代码转变为对应的汇编代码指令编译的作用就是, 把
C语言代码转变成相应的汇编代码编译这个过程的细节一般还会分为:
语法分析词法分析语义分析符号汇总更加细节的内容不在这里赘述。(以后有机会再详细介绍一下)
1.2.3 汇编 Link to 1.2.3 汇编
汇编 是对 汇编代码 进行的操作, 汇编的作用是将 汇编代码 转换成 计算机可以直接识别的 机器指令 即, 二进制指令。
对 test.s 文件进行汇编操作:
📌
✔️小知识:
gcc -c (经过预编译的文件) 或 gcc (经过预编译的文件) -c(注意此处 -c 中, c 为小写)可以对汇编代码文件进行汇编操作, 将生成的二进制指令 输出到对应的以.o为后缀的文件中.o后缀的文件, 就是GCC环境生成的目标文件查看
.o目标文件:
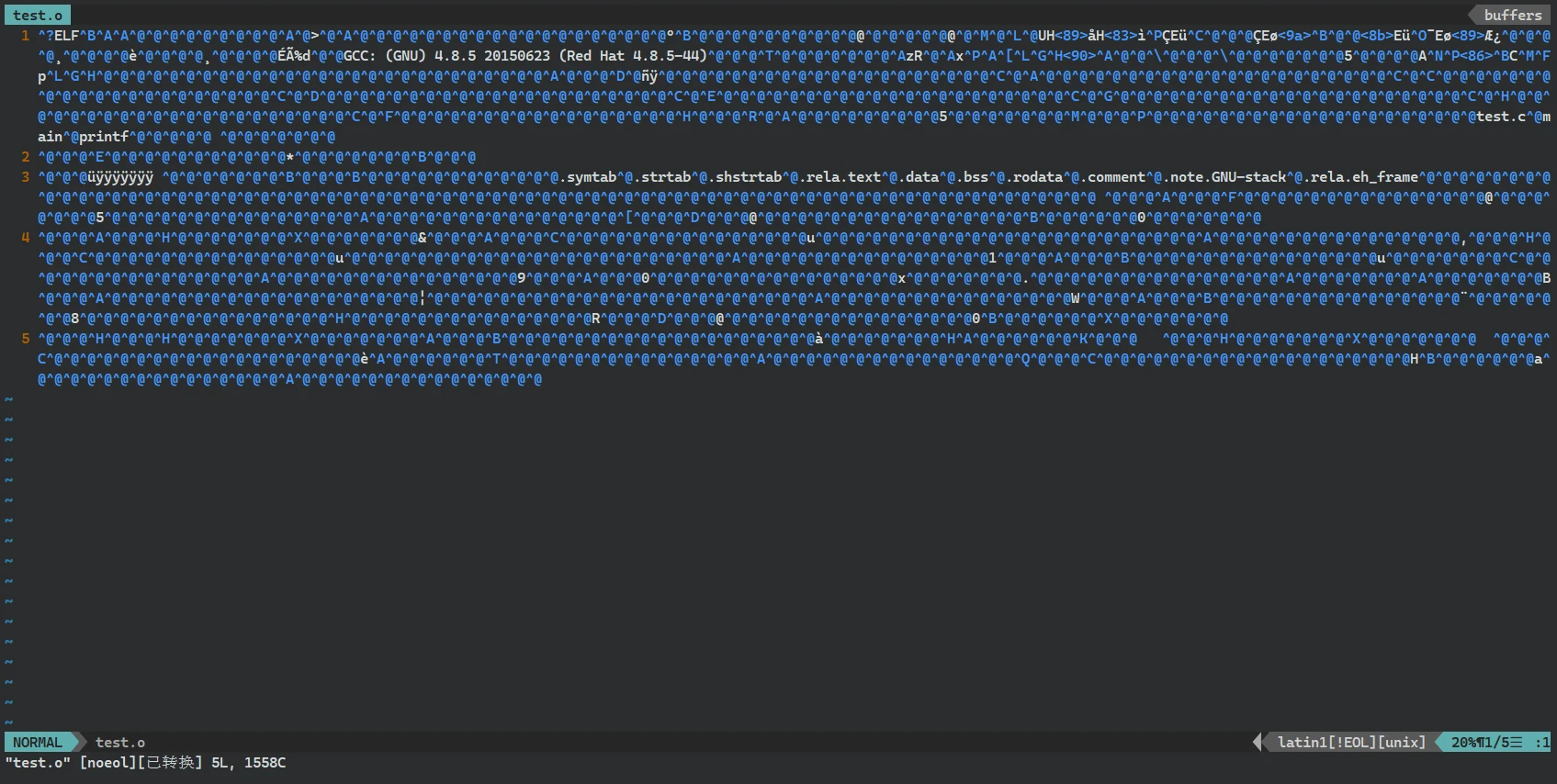
vim打开, 可以看出 目标文件几乎都是乱码。其实只是计算机可以直接识别的二进制的指令。所以,
汇编操作是将汇编代码转换为机器指令(二进制指令)。
以上三段过程, 是翻译环境中 编译的整个过程, 而翻译最重要的环节之一, 还有: 链接:
1.2.4 链接 及 结果 Link to 1.2.4 链接 及 结果
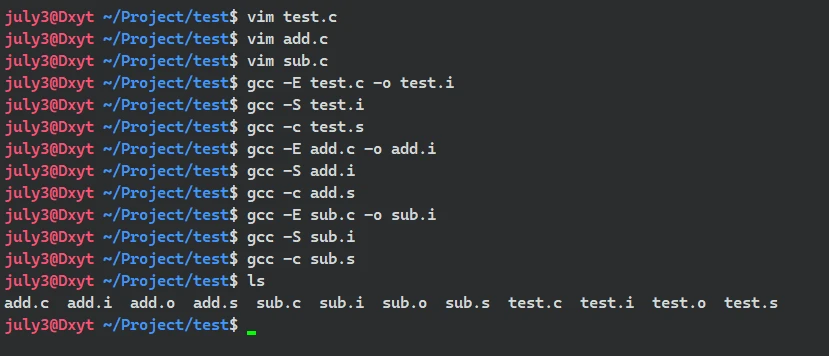
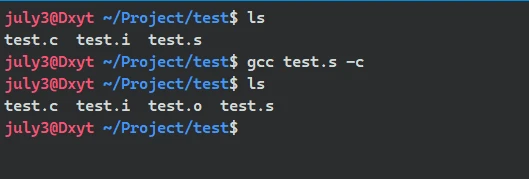
链接, 是对项目中所有的目标文件进行链接的, 如果想要展示出链接的作用, 可以编写多个 .c 文件进行编译, 再将所有的 .o 文件 进行链接。
📌
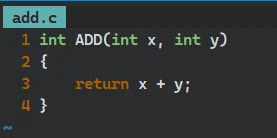
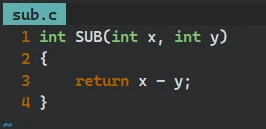
// add.c int ADD(int x, int y) { return x + y; }// sub.c int SUB(int x, int y) { return x - y; }// test.c #include <stdio.h> extern int ADD(int x, int y); extern int SUB(int x, int y); int main() { int x = 100; int y = 20; int sum = ADD(x, y); int dev = SUB(x, y); printf("sum = %d\n", sum); printf("dev = %d\n", dev); return 0; }
vim:
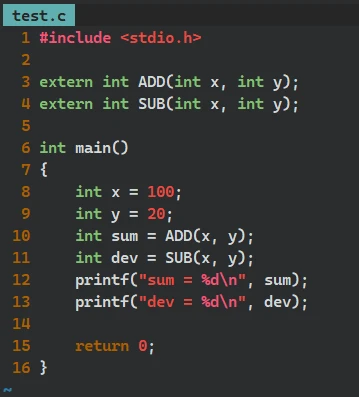
然后, 分别对
add.c、sub.c、test.c三个.c文件, 预编译、编译、汇编:
最终生成对应的:
add.o、sub.o、test.o最后对
所有的目标文件进行链接
(用户不用主动在意静态库, 链接器会自动链接):
✔️小知识:
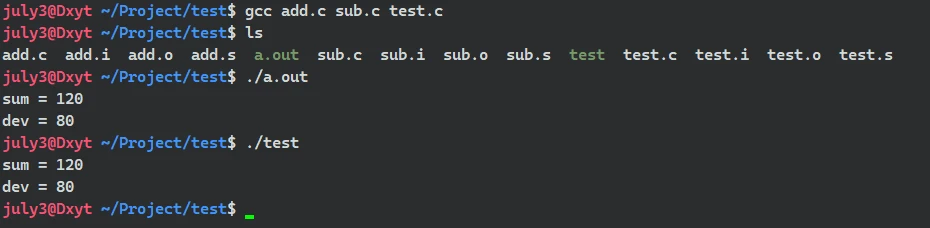
gcc (所有的目标文件)即可将所有目标文件链接在一起, 生成可执行程序。 后接-o (指定程序名)gcc (所有的目标文件) -o (指定程序名)可生成指定文件名的可执行文件为了做对比, 直接对
add.c、sub.c、test.c进行编译链接方便进行对比:
直接编译链接, 不指定文件名, 生成
a.out可执行程序 >分别运行
test、a.out
test、a.out两程序运行结果相同, 说明 拆解过程的编译链接 及 直接的编译链接 结果是一样的可以说明, 一个项目 在翻译环境中的整个过程确实为:
- 编译 a. 预编译
(删除原代码中的注释、对头文件进行包含.展开、对宏符号进行转换 等)b. 编译(将 C 语言代码文件 转换为 对应的汇编代码文件)c. 汇编(将 汇编代码文件 转换为 对应的机器指令文件(目标文件))- 链接
(将 所有目标文件 及 静态库 链接 生成可执行文件)那么, 项目文件从
.c到 可执行文件的过程 可以简单的详细为: