![[C++-STL] set和map容器的相关介绍](https://dxyt-july-image.oss-cn-beijing.aliyuncs.com/202306251815314.webp)
Table of Contents
set 和 map 是C++ - STL 中非常重要的两个容器, 上一篇文章介绍了 二叉搜索树。
而 set 和 map 的底层就是由一种二叉搜索树来实现的——红黑树
本篇文章先来介绍一下 set 和 map 简单的介绍, 以及相关接口的使用
关于set Link to 关于set
set Link to set
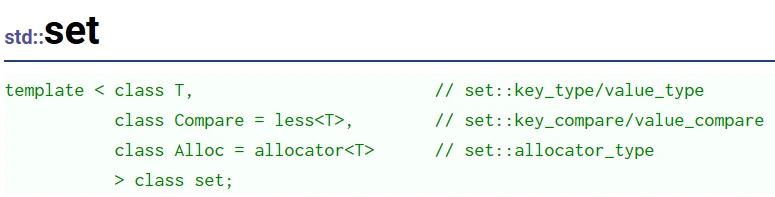
按照set模板的定义, 其模板参数的意义是:
第一个模板参数T——存储元素类型;第二个模板参数——元素比较的仿函数;第三个模板参数——分配器
第二个和第三个模板参数 都给定了缺省值, 本篇文章对其使用的介绍暂时不涉及 后两个模板参数的改变
官方文档中对set的介绍是:

总结一下就是: set 是一个由二叉搜索树实现的用于存储 唯一的 不可修改的 元素 的容器;并且, 存储的元素按照给定的比较方式进行严格的排序 再解释一下就是: set 以二叉搜索树的形式存储元素, 并且树中没有重复的元素, 存储的元素都是const修饰的 不可修改, 并且存储元素时会按照给定的 cmp方式(模板参数中的 Compare) 进行排序
其实这里的二叉搜索树再具体一点, 就是红黑树
除了存储唯一元素的
set, STL中还存在另一个可以存储重复元素的容器:multiset与set的区别仅在于 其可以存储重复的元素
set 的常用接口 Link to set 的常用接口
1. insert Link to 1. insert

insert 最基本也最常用的用法就是 直接插入指定类型的一个元素: \
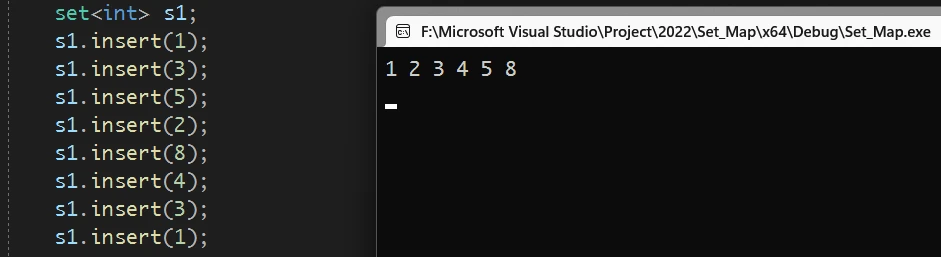
可以看到 插入的元素会自动排好顺序, 并且重复插入相同的元素只会插入一次
insert 也可以指定位置插入指定的值, 但是这种方式很少使用, 因为set是有严格的结构要求的。 为了再插入元素时不破坏结构, 即使指定位置插入, 也有可能不在指定的位置插入元素。所以, 一般在 已经知道将此元素插入此位置不会造成结构的破坏 时才可能使用这种方式
最常用的还是直接插入元素
仔细看 C++98 中
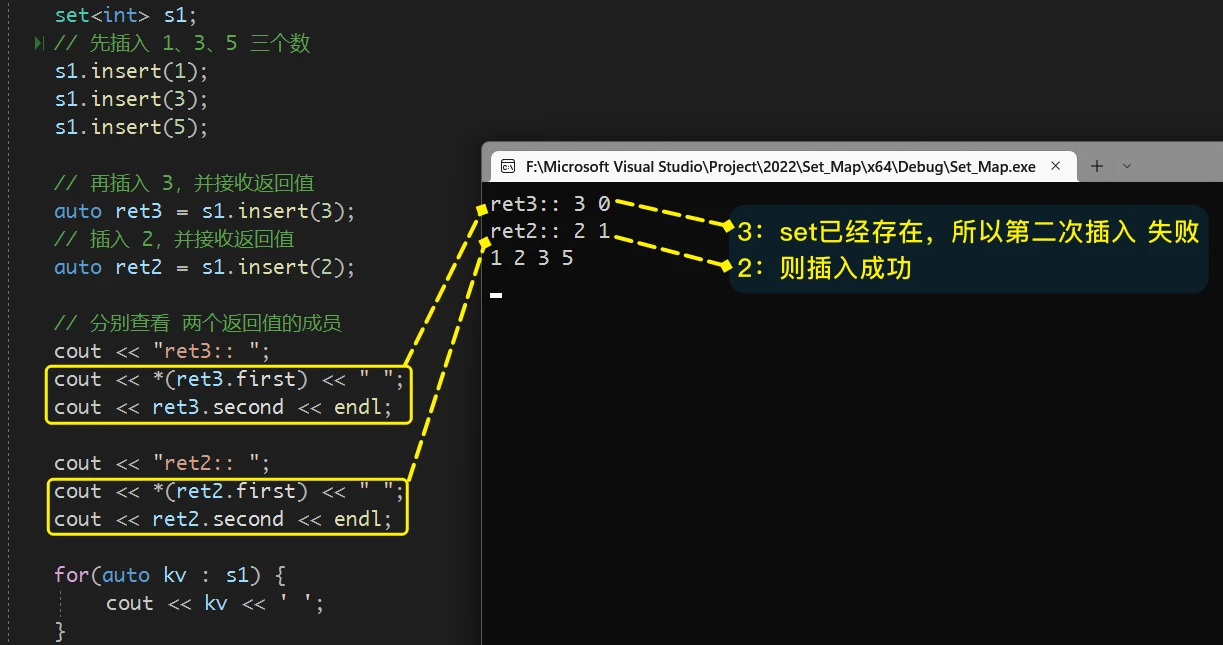
insert直接插入元素的用法, 其返回值是:pair<iterator, bool>
pair是什么?pair是一对, 一双的意思
pair 也是一个类模板, 有两个模板参数:
T1: 第一个元素类型;T2: 第二个元素类型在
insert返回值中两个元素类型分别是iterator和bool为什么要返回一个
pair<iterator, bool>类型的数据呢?查看
insert第一个版本关于返回值的描述是:
返回
pair类型数据的原因, 其实是 由于set存储的是唯一的元素, 所以会存在插入失败的情况(当set中已经存在将要插入的元素, 此时的插入操作就会失败), 而某些场景需要判断当前插入操作是否成功, 而某些场景又需要获取插入元素的位置, 但是函数的返回值只能由一个, 所以就使用了pair来将 元素的位置 和 插入是否成功 存储起来, 返回 pair类型的数据就可以同时 知道元素的位置 和 本次插入是否成功即, 当
set中没有将要插入的元素时, 插入就会成功, 并会将 插入元素的位置 和true(表示插入成功) 存储到pair对象中 并返回当
set中已经存在将要插入的元素时, 插入就会失败, 并会将 已经存在的元素的位置 和false(表示插入失败) 存储到pair对象中 并返回举个例子:
因为
set不存储重复数据所以才会如此, 而multiset的insert就不需要这样



2. 迭代器相关 Link to 2. 迭代器相关
| 接口 | 功能 |
|---|---|
begin() | 返回 首元素 正向迭代器 |
end() | 返回 末元素 正向迭代器 |
set 与其他容器一样 常用两个函数取迭代器, 一个 begin() 用来取首元素正向迭代器, 一个 end() 用来取末元素正向迭代器
关于
set的迭代器需要注意的是:set迭代器表示的内容是无法修改的即, 即使是
iterator而不是const_iterator, 其表示的内容也是无法修改的:
原因其实是, STL 设计
set时,iterator其实也是const修饰过的iterator:
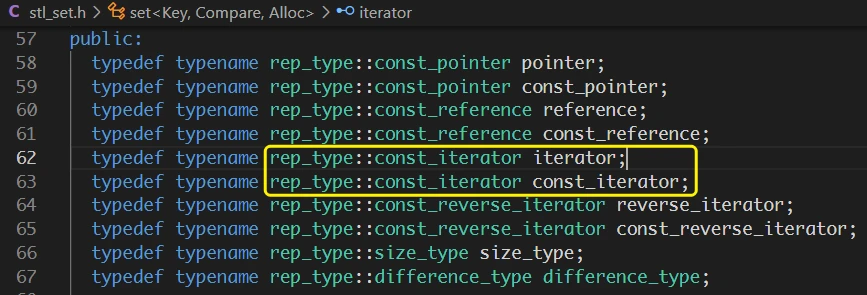
查看
STL关于set的源码, 就可以看到iterator和const_iterator都是对rep_type::const_iterator的typedef

set 关于迭代器的其他接口函数还有: cbegin() cend() rbegin() rend() crbgin() crend() 无非是关于 反向迭代器 和 const迭代器
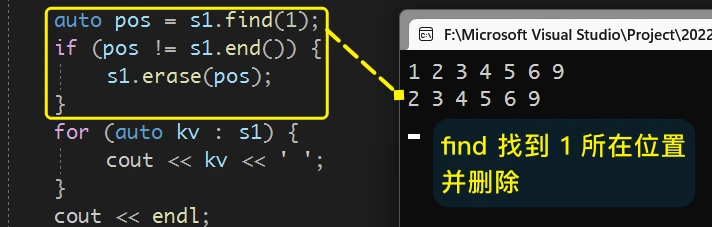
3. find Link to 3. find

find 的用法和作用就非常的简单了, 只需要传入需要查找的数据内容 就可以使用
find 的返回值是一个迭代器, 按照文档的介绍: 如果可以在set中找到指定的数据, 则返回这个数据位置的迭代器; 否则 返回 end()
find一般与erase一起使用, 先用find查找数据位置迭代器, 再用erase删除
4. erase Link to 4. erase

erase 删除元素接口, 有三个不同的重载版本:
- 删除指定位置的数据
- 删除指定值
- 删除两个迭代器区间内的数据
这三个版本都是可能会用到的
**删除指定值版本: **
只需要在调用时传入值就可以完成指定值的删除
即使是
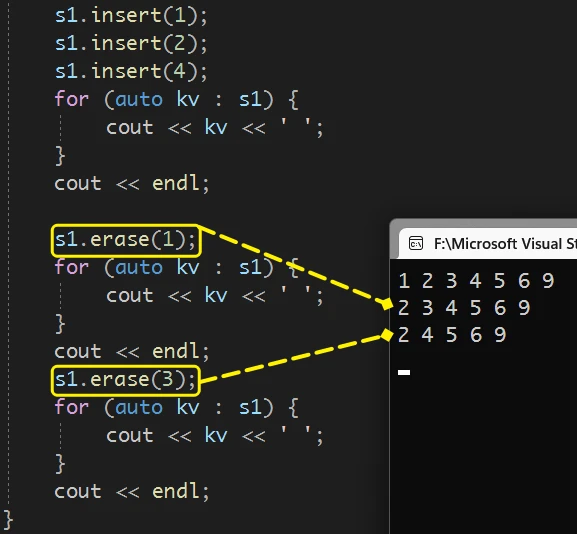
set中没有的值, 也不会出错:
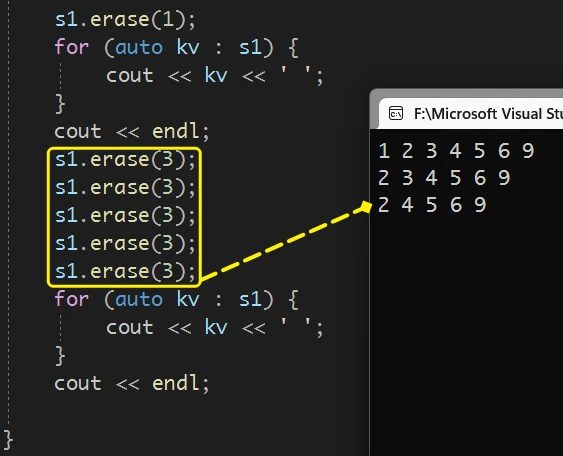
多次重复删除 3, 也不会出现问题
并且 此版本存在返回值, 返回值就是 删除的这个数据
**删除指定位置版本: **
erase删除指定位置, 一般需要先使用find在set中找到相应的位置, 然后再erase进行删除:
当find找到了确定值的位置时, 就可以正常的删除
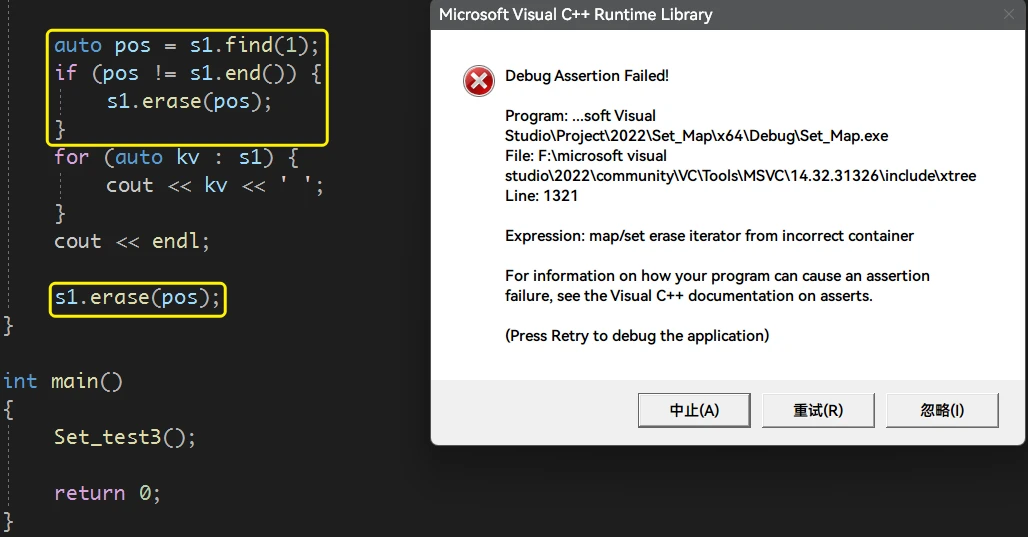
那么 当删除
pos之后, 不改变pos, 再次删除会发生什么?
很明显会报错, 此时其实是迭代器失效了,
pos已经不再表示set中存储的3了, 意义已经变了STL提供的通用的
find也可以找指定数据的位置, 但是效率终究不如set本身的因为 算法提供的通用的
find是 根据提供的迭代器区间进行遍历查找, 而set自己的find是根据二叉搜索树的特性而实现的logN时间复杂度的算法
删除迭代器区间内数据的版本
举个例子:
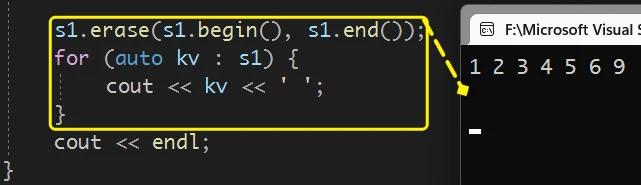
当 传入
set的begin()和end()时, 就会把set内的所有数据都删除不过 这个版本一般不是在这种情况下使用的
set内存储的数据, 是按照给定的规则排好序的, 所以 当需要删除某个区间范围内的数据时, 一般会用到 这个版本的删除接口而取
set中的一个指定的区间范围, 将会用到下面介绍的两个接口函数:lower_boundupper_bound
5. lower_bound 和 upper_bound Link to 5. lower_bound 和 upper_bound


这两个接口函数, 在之前的容器中都没有见过
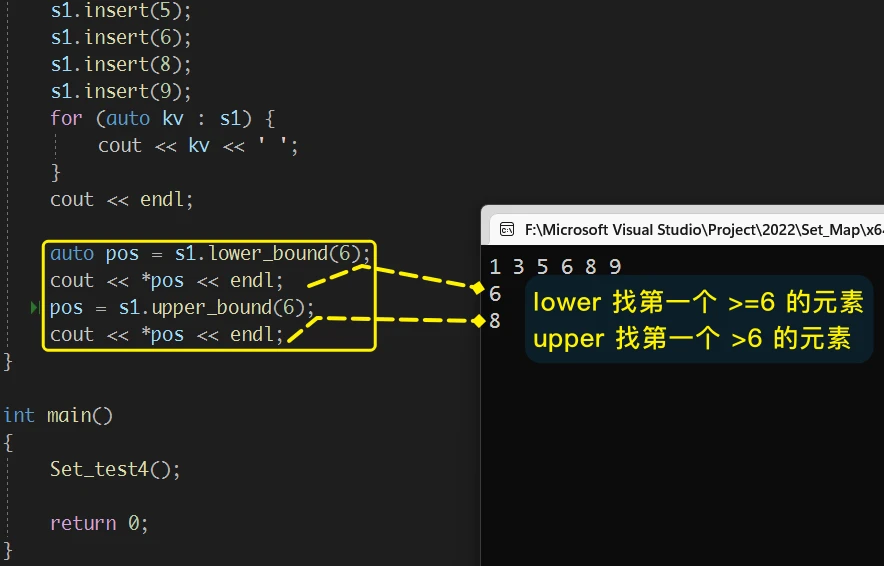
其实这两个接口函数的作用是 指定一个值, 在set中找 >=(lower) 或 >(upper) 这个值的第一个元素, 并返回其迭代器
例如: 在一个 set 中, 存储的元素是: 1 3 5 6 8 9 , 则, 使用 lower_bound(6) 会返回 6 的迭代器;而 使用 upper_bound(6) 会返回 8 的迭代器
即, lower_bound() 返回 第一个**>=指定值的元素的迭代器, upper_bound() 返回 第一个>**指定值的元素的迭代器
举个例子:
使用 这两个接口函数 就可以实现 指定区间删除数据:
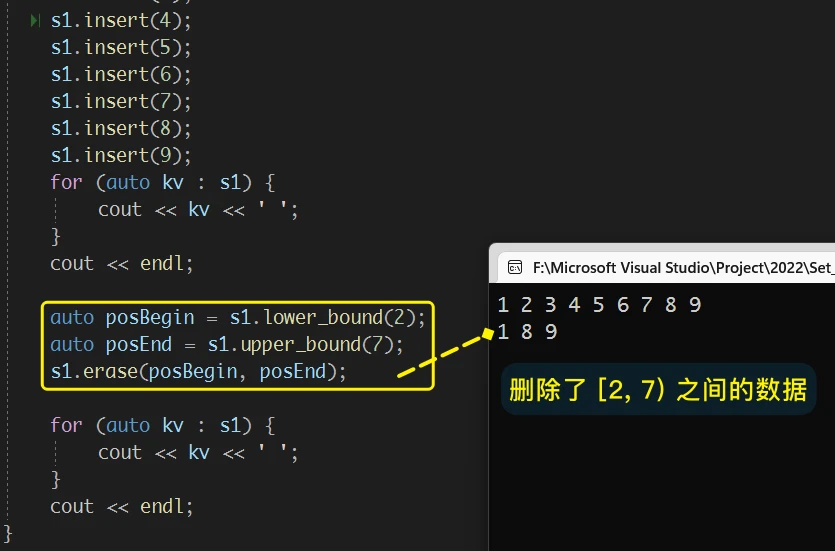
比如, 对于
1 2 3 4 5 6 7 8 9 10删除[2, 7)之间的数据:
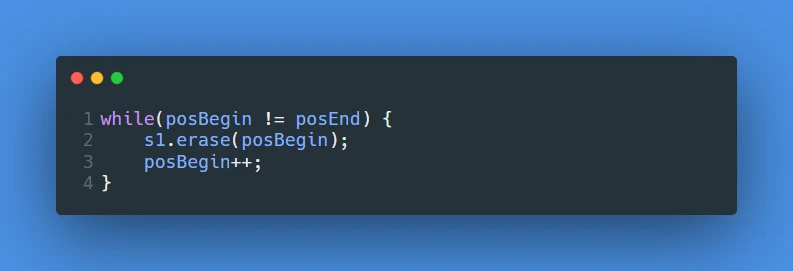
注意: 由于erase的迭代器失效、以及erase没有有效的迭代器返回值问题, 不能使用类似下面这样的代码, 对
set的一个迭代器区间进行删除数据:
原因是 执行
erase之后posBegin这个迭代器表示的意义已经失效了, 不能再按照其原本的意义进行改变 即 此时的posBegin已经不是set中某个值的位置了, 再直接对其使用某些操作其实是对野指针的操作, 是会发生错误的
6. count Link to 6. count

set 存在一个接口函数叫 count, 这个函数在 set 里好像没有什么太大的用途
因为 count 的作用是, 统计 相同值的个数并返回
在 set 中, 不能存储重复的数据, 所以 count 只能返回 0 或 1. 所以 count 在 set 里的作用更像是 验证当前set中是否存在某个值
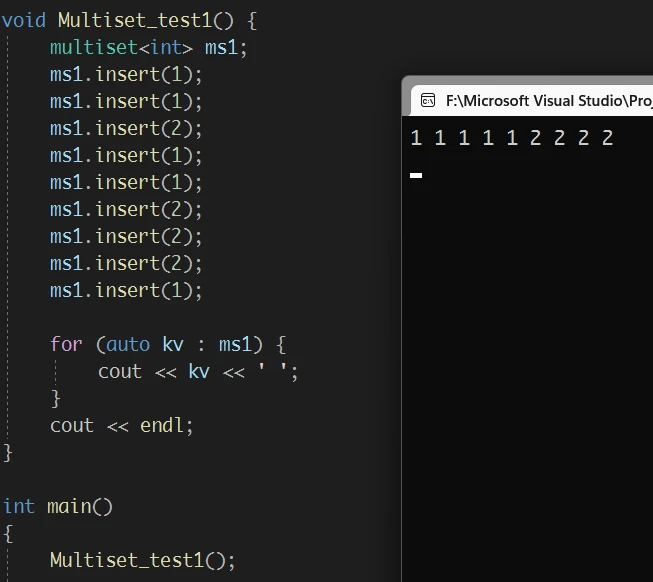
multiset Link to multiset
multiset 与 set 略有不同, multiset 可以存储重复的数据, 除此之外 与 set 没有什么区别
multiset 常用的接口 Link to multiset 常用的接口
由于 multiset 结构的不同, 所以 其某些常用的接口函数的用法不太一样
这里只介绍一下 用法与set不相同的接口函数
1. find Link to 1. find

由于 multiset 可以存储重复的数据, 所以 find 也就有可能找重复的数据, 不过 找到重复的数据 find 只返回重复的第一个数据的迭代器
2. equal_range Link to 2. equal_range

find 是返回重复数据的第一个迭代器, 而 equal_range 则是返回找到的重复的数据的 首尾范围, 并以 pair<iterator, iterator> 返回
3. erase Link to 3. erase

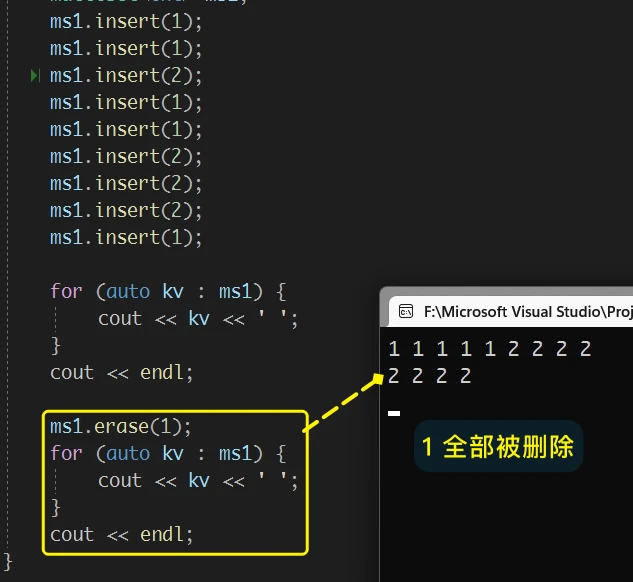
erase 接口的功能, 与 set 中不同的 只有删除指定数据的功能
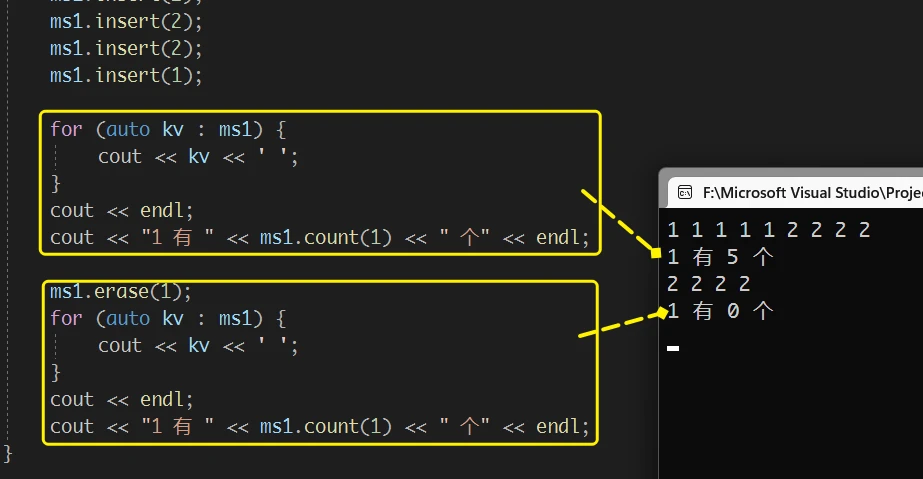
set 中的 erase, 只删除指定的一个数据, 而 multiset 中的erase 是将结构中 相同的数据全部删除:
4. count Link to 4. count

在 set 中, count 只能返回 1 或 0
而由于 multiset 可以存储重复的数据, 所以 count 就可以按照其功能 返回指定数据的个数
关于 map Link to 关于 map
map Link to map
map 与 set 相似, 但又有一些不同, map 和 set 的底层都是由 红黑树 实现的
但不同的是, map 更像是 之前介绍的 K-V二叉搜索树
map 存储的单个数据的类型是 pair<T1, T2> , 而 set 的单个数据 就只是指定的单个类型(当然也可以指定一个pair, 但是如果这样 为什么不直接用map呢?)

查看 map 的模板参数:
第一个模板参数——关键字类型;第二个模板参数——关键字对应的值得类型;第三个模板参数——比较规则的仿函数;第四个模板参数——分配器

map 的常用接口 Link to map 的常用接口
上边介绍过 set的常用接口之后, map 的常用接口的了解 就会非常的简单
1. insert Link to 1. insert

map 中 insert 的使用方式与 set的insert 相同, 但是由于 map的数据类型是 pair, 所以 insert传参就需要传入pair对象
那么就需要了解如何创建
pair对象
pair的拥有两个成员变量:first和second;first是 T1类型的, second 是 T2类型的
pair作为一个类, 当然可以调用构造函数实例化对象:
或者 在调用
insert时实例化匿名对象:
但是这两种实例化对象的方式, 都需要显式指定数据类型, 还有一个方法 可以更加方便的实例化对象:
make_pair:
make_pair是一个函数模板, 作用是实例化并返回一个匿名对象但是,
make_pair使用时, 可以通过传入的参数来推导参数的类型所以
insert时使用make_pair省去了 显式指定数据类型的步骤, 方便了很多



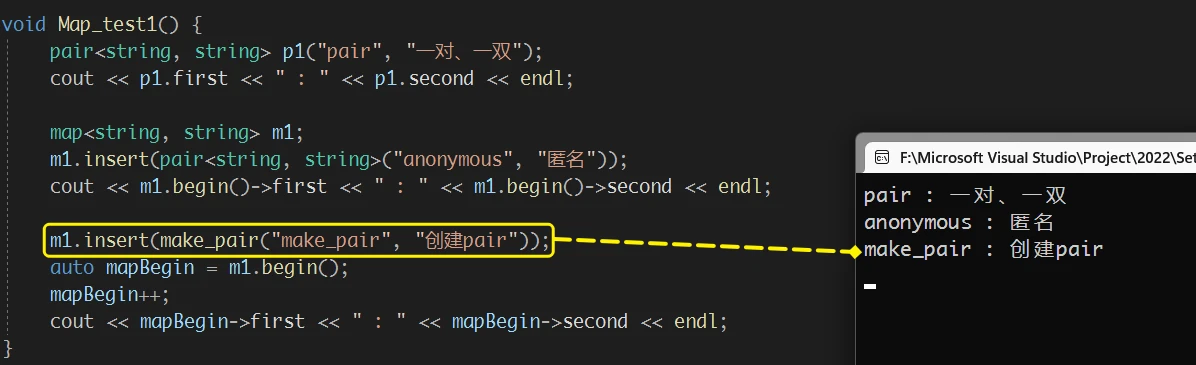
由于结构的限制, map的insert 最常用的版本还是 不指定位置插入数据 的版本
此版本的返回值是一个 pair<iterator, bool>, 与 set 中的相同 返回的 pair存储的是插入元素的迭代器和插入是否成功的记录
2. 迭代器相关 Link to 2. 迭代器相关
map 迭代器相关的接口函数依旧是 正向、反向、是否const 这几种组合, 也没有什么需要注意的
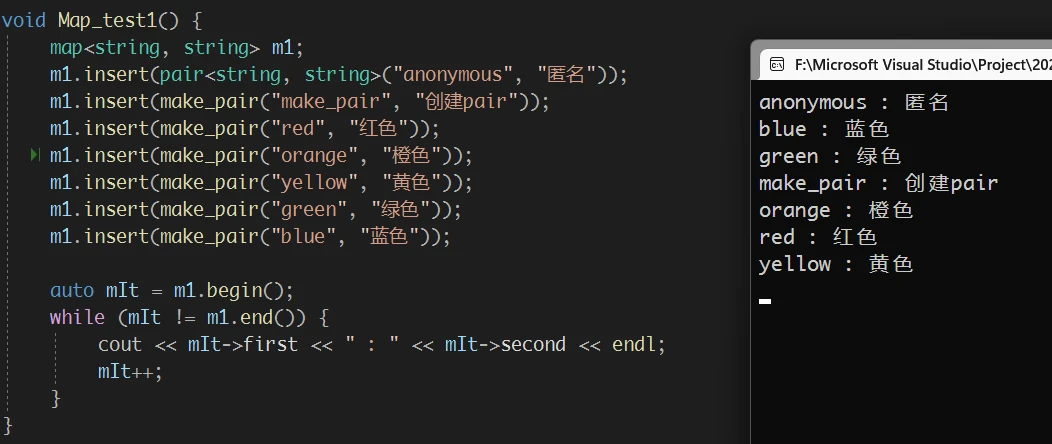
需要注意的是 map 的迭代器本身:
map 迭代器指向的是 map的数据, 而 map存储的数据是 pair, 所以通过迭代器访问数据, 不能直接解引用迭代器, 而是需要再通过迭代器去访问 pair的成员变量
3. find Link to 3. find

map 的 find 是通过 关键字 来查找相应的节点的, 也就是通过 pair 中的 first变量:
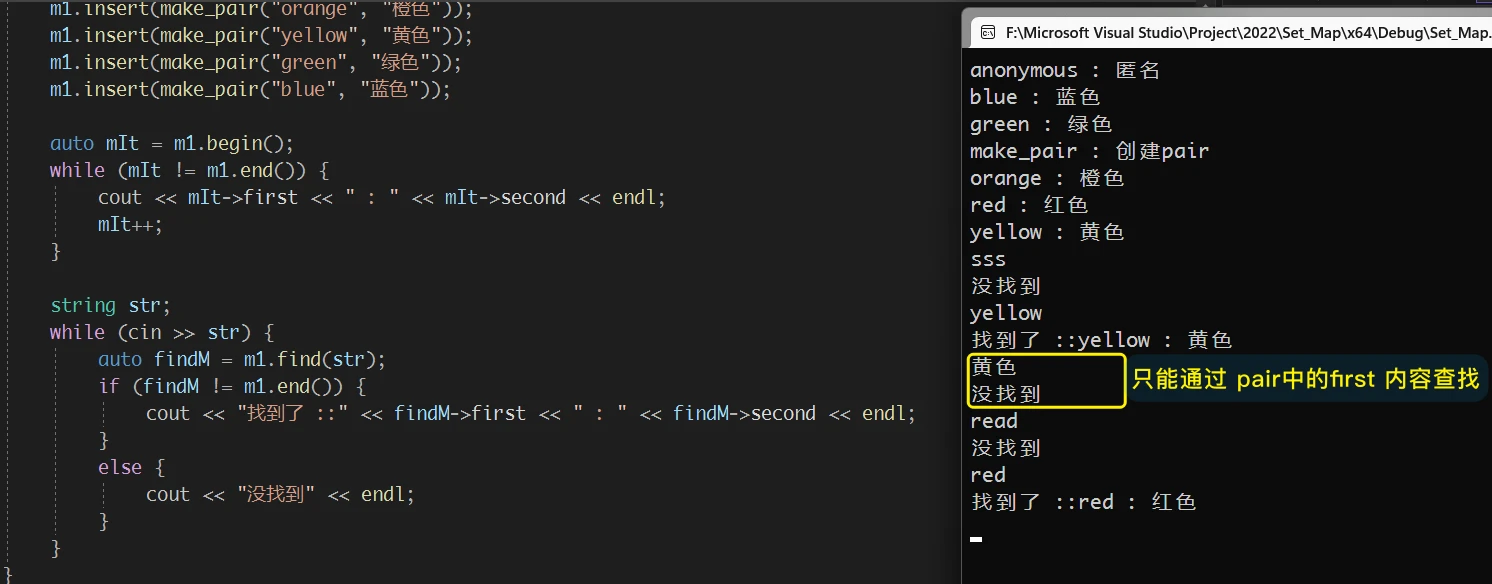
如果没有找到相应的节点, 就会返回 map.end()
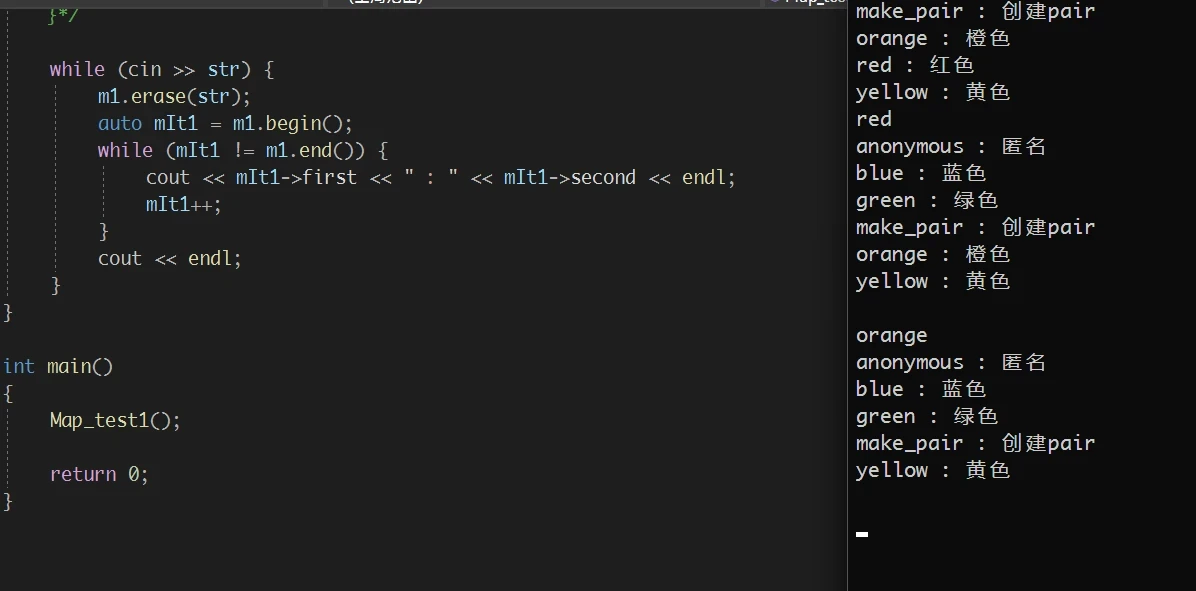
4. erase Link to 4. erase

map 的erase 也没有什么特别的用法, 几乎与set一模一样, 不过还是需要注意:
- 迭代器失效的问题
- 通过
key(pair的first变量) 删除
5. operator[] * Link to 5. operator[] *
在前一篇文章 介绍 K-V 二叉搜索树时, 介绍了一种K-V二叉搜索树的使用场景: 统计某种物品的个数:
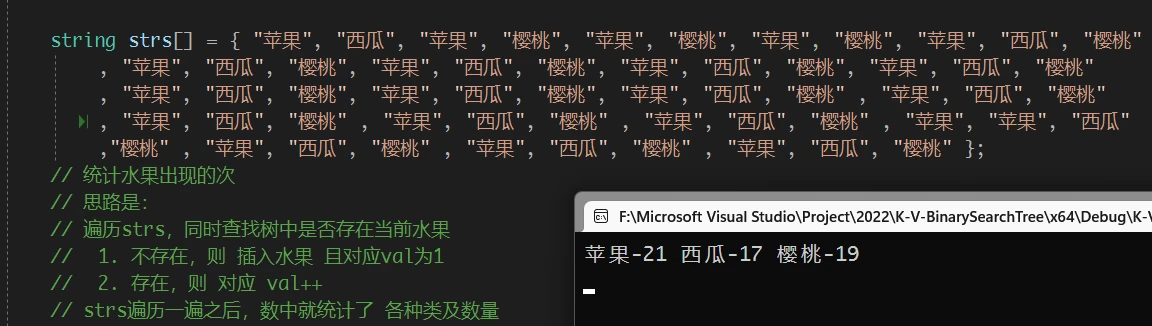
map 当然也可以做到:
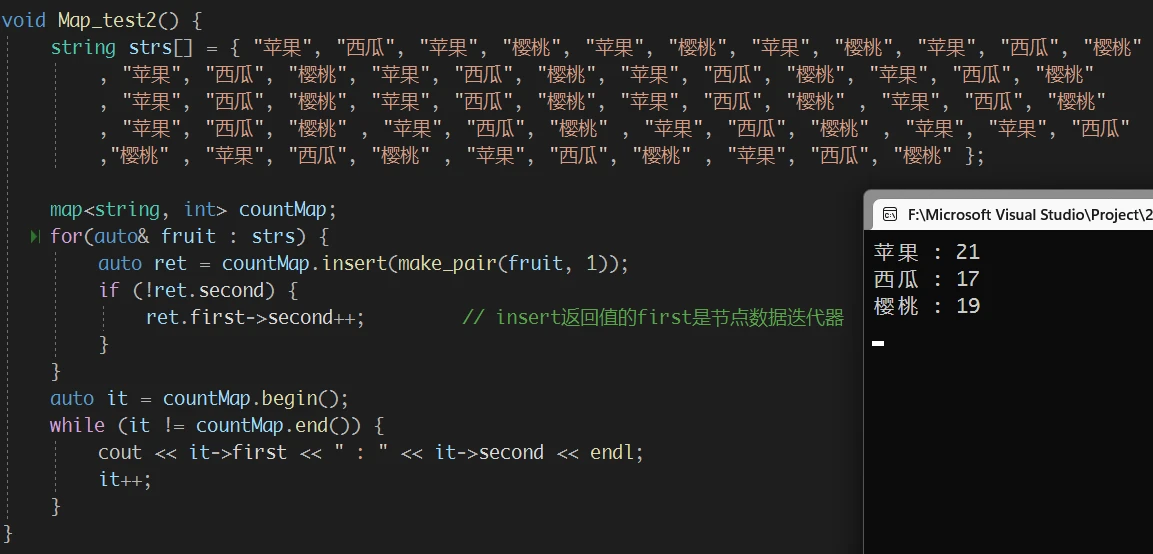
使用 map 显式通过 与 K-V二叉搜索树 相似的解决方式, 达到了相同的目的, 但是过于繁琐
使用 map 还可以更简单:

这是 map 中 operator[] 可以达到的效果
map中 [] 的重载函数是怎么实现的才能达到这样的效果?

这是文档中关于 operator[] 的介绍, 翻译一下就是:
这个函数的作用是: 返回指定关键字对应的值的引用;如果map不存在此关键字, 则将此关键字插入其中, 并返回其对应值的引用
调用此函数 等效于: (*((this->insert(make_pair(k,mapped_type()))).first)).second

operator[] 返回值类型是 mapped_type&
map的文档显示:

mapped_type 是map的第二个模板参数, 其实就是关键字映射的值得类型
(*((this->insert(make_pair(k,mapped_type()))).first)).second 是什么意思?
其实这一句代码分析一下, 可以分析出 operator[] 可能是这样定义的:

在C++中, 内置类型(
int、double、char等)也可以看作是类, 可以使用一般类实例化对象的方式实例化数值
那么这段代码的意思就是, 向map中 insert 一个 以 k 作为first,以 mapped_type类型的缺省值 作为second 的pair, 并接收 insert的返回值
然后再根据返回值, 访问插入节点的 second变量 并返回
在 上面的记录水果个数的例子中, 返回的就是 某种水果的个数。如果是 苹果的个数, 就说明刚刚记录的是苹果, 就需要将苹果的个数++
map 中 operator[] 是一个非常重要, 也非常细节的重载函数, 需要牢记